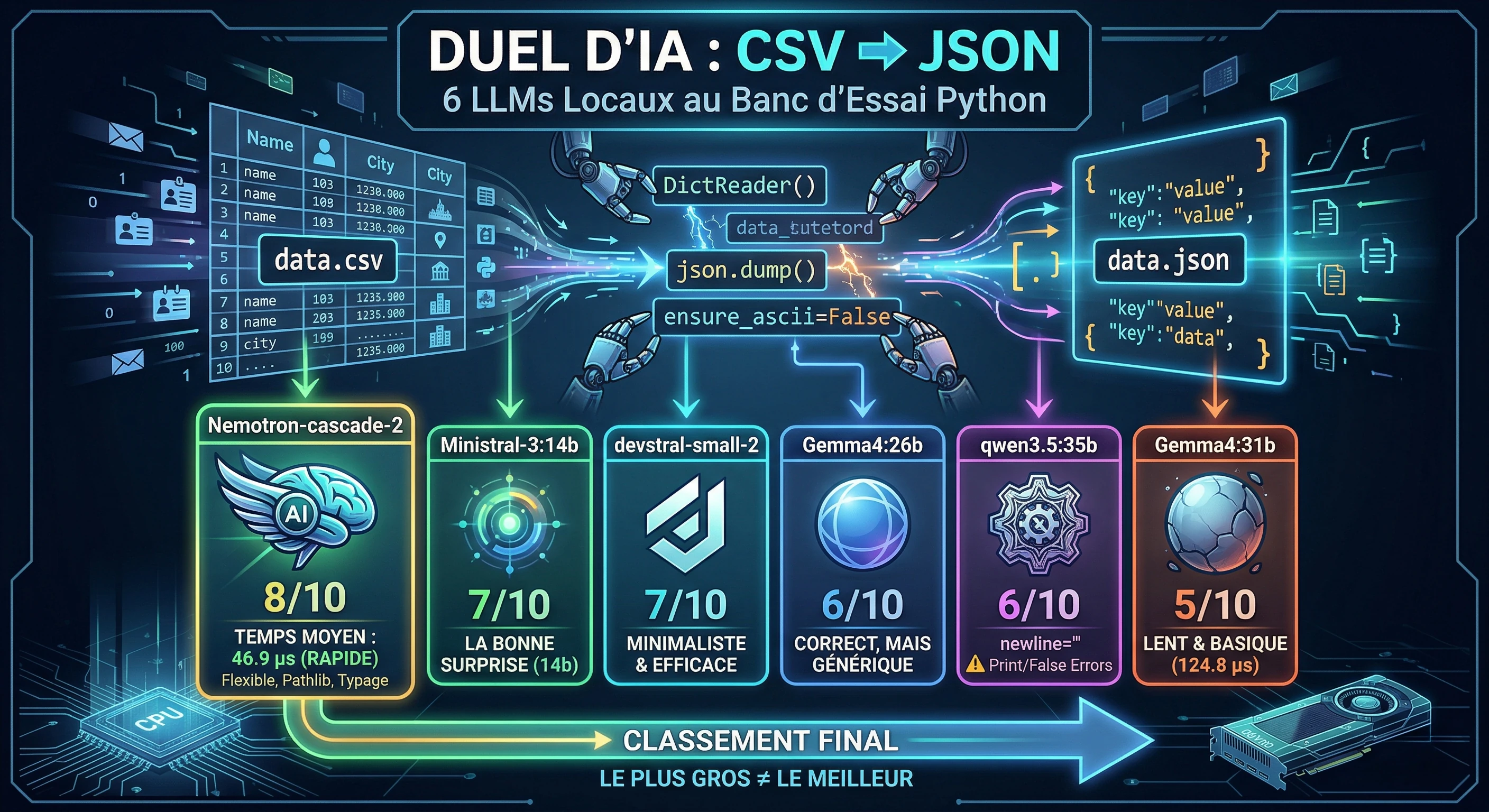
Prompt donné aux modèles : « Je voudrais que tu me fasses une fonction en Python pour parser un fichier CSV et le transformer en JSON. »
Un même prompt, six modèles différents, tous exécutés en local via Ollama. L'objectif : voir comment chaque LLM interprète une demande simple et comparer la qualité, la performance et la concision du code produit.
Le matériel utilisé
Les modèles ont été exécutés sur un serveur dédié avec la configuration suivante :
| Composant | Détail |
|---|---|
| CPU | Intel Xeon W-2125 @ 4.00 GHz (4 cœurs / 8 threads) |
| RAM | 32 Go DDR4 |
| GPU | 2× NVIDIA Quadro P5000 (16 Go VRAM chacune) |
| OS | Ubuntu 24.04.4 LTS |
| Runtime | Ollama dans Docker |
Le protocole de test
Pour chaque fonction générée, un script Python automatisé effectue :
- Test fonctionnel — La fonction est appelée avec un fichier CSV de 10 lignes. Le JSON produit (fichier ou retour mémoire) est validé : structure, clés, nombre de lignes, correspondance exacte avec les données source.
- Benchmark de vitesse — 1 000 exécutions consécutives, temps moyen mesuré en microsecondes.
- Mesure mémoire — Pic de consommation mémoire mesuré via
tracemalloc.
Le CSV de test :
nom,prenom,age,ville,email
Dupont,Jean,34,Paris,jean.dupont@email.fr
Martin,Sophie,28,Lyon,sophie.martin@email.fr
...Les résultats
| Modèle | Fonctionnel | Temps moyen | Mémoire pic | Note |
|---|---|---|---|---|
| Nemotron-cascade-2 | ✓ | 46.9 µs | 34.0 KB | 8/10 |
| devstral-small-2 | ✓ | 61.7 µs | 38.0 KB | 7/10 |
| Gemma4:26b | ✓ | 65.0 µs | 38.1 KB | 6/10 |
| qwen3.5:35b | ✓ | 74.0 µs | 38.0 KB | 6/10 |
| ministral-3:14b | ✓ | 74.5 µs | 38.0 KB | 7/10 |
| Gemma4:31b | ✓ | 124.8 µs | 38.1 KB | 5/10 |
Tous les modèles produisent un code fonctionnel. Les différences se jouent sur l'architecture, la flexibilité et l'efficacité.
Analyse modèle par modèle
1. Nemotron-cascade-2 — 8/10
def csv_to_json(csv_path, json_path=None, encoding="utf-8"):
csv_path = Path(csv_path)
if not csv_path.is_file():
raise FileNotFoundError(f"Le fichier CSV n'existe pas : {csv_path}")
with csv_path.open(newline='', mode='r', encoding=encoding) as f:
reader = csv.DictReader(f, delimiter=',')
data = [row for row in reader]
json_str = json.dumps(data, ensure_ascii=False, indent=2)
if json_path:
json_path = Path(json_path)
json_path.parent.mkdir(parents=True, exist_ok=True)
json_path.write_text(json_str, encoding=encoding)
return dataLe meilleur du lot. C'est le seul à proposer les trois modes d'utilisation : écriture fichier, retour en mémoire, ou les deux. Il utilise pathlib (plus moderne que os.path), crée automatiquement les répertoires parents, et offre un paramètre encoding configurable. Le typage est présent (List[Dict[str, Any]]), la docstring est complète avec des paramètres documentés.
Point faible : il sérialise systématiquement en JSON string (json.dumps) même quand on ne demande que le retour en mémoire — une opération inutile qui gaspille du CPU. Malgré cela, il reste le plus rapide grâce à pathlib.write_text() qui est plus efficient que le pattern open()/json.dump() pour les petits fichiers.
2. ministral-3:14b — 7/10
def csv_to_json(csv_file_path, json_file_path=None):
data = []
with open(csv_file_path, mode='r', encoding='utf-8') as csv_file:
csv_reader = csv.DictReader(csv_file)
for row in csv_reader:
data.append(row)
if json_file_path:
with open(json_file_path, mode='w', encoding='utf-8') as json_file:
json.dump(data, json_file, indent=4, ensure_ascii=False)
return None
else:
return json.dumps(data, indent=4, ensure_ascii=False)Bonne surprise pour un "petit" modèle (14b). C'est le seul autre modèle (avec Nemotron) à proposer un double mode : écriture fichier ou retour en mémoire. Le code est propre, sans fioritures. La docstring explique clairement les deux comportements.
Point faible : pas d'utilisation de pathlib, pas de gestion d'erreur. Mais pour un modèle de cette taille, c'est un excellent résultat — il a bien compris l'ambiguïté du prompt et a fait un choix intelligent.
3. devstral-small-2 — 7/10
def csv_to_json(csv_file_path, json_file_path):
data = []
with open(csv_file_path, mode='r', encoding='utf-8') as csv_file:
csv_reader = csv.DictReader(csv_file)
for row in csv_reader:
data.append(row)
with open(json_file_path, mode='w', encoding='utf-8') as json_file:
json.dump(data, json_file, indent=4, ensure_ascii=False)Le plus minimaliste — et c'est une qualité. Pas de try/except inutile, pas de print(), pas de if __name__. Juste la fonction, propre et directe. C'est exactement ce qu'on demandait. En bonus, c'est le deuxième plus rapide du benchmark.
Point faible : aucune flexibilité (pas de mode retour mémoire, pas de paramètre encoding). Mais le prompt ne le demandait pas, donc c'est une lecture correcte de la consigne.
4. Gemma4:26b — 6/10
def csv_to_json(csv_filepath, json_filepath):
data = []
try:
with open(csv_filepath, encoding='utf-8') as csv_file:
csv_reader = csv.DictReader(csv_file)
for row in csv_reader:
data.append(row)
with open(json_filepath, 'w', encoding='utf-8') as json_file:
json.dump(data, json_file, indent=4, ensure_ascii=False)
print(f"Conversion réussie ! Fichier créé : {json_filepath}")
except FileNotFoundError:
print(f"Erreur : Le fichier '{csv_filepath}' est introuvable.")
except Exception as e:
print(f"Une erreur est survenue : {e}")Correct mais sans valeur ajoutée. Structurellement quasi-identique à Gemma4:31b. La boucle for row / append est plus verbeuse que list(reader) sans bénéfice. La gestion d'erreur par print() est un anti-pattern en production — on préfère lever des exceptions pour laisser l'appelant décider.
5. qwen3.5:35b — 6/10
def csv_to_json(input_file_path, output_file_path):
data = []
try:
with open(input_file_path, mode='r', newline='', encoding='utf-8') as csv_file:
dict_reader = csv.DictReader(csv_file)
data = list(dict_reader)
with open(output_file_path, mode='w', encoding='utf-8') as json_file:
json.dump(data, json_file, ensure_ascii=False, indent=4)
print(f"Conversion réussie : {input_file_path} -> {output_file_path}")
return True
except FileNotFoundError:
print("Erreur : Le fichier spécifié est introuvable.")
return False
except Exception as e:
print(f"Erreur lors du traitement : {e}")
return FalseSeul modèle à ajouter newline='' dans l'appel à open(), ce qui est la bonne pratique selon la documentation du module csv (évite les problèmes de saut de ligne sur Windows). Bon point. Le retour booléen est une idée intéressante pour du scripting.
Point faible : la gestion d'erreur par print() + return False rend le débogage difficile — on perd le traceback. Pour 35 milliards de paramètres, on aurait pu espérer une approche plus sophistiquée.
6. Gemma4:31b — 5/10
def csv_to_json(csv_file_path, json_file_path):
try:
with open(csv_file_path, mode='r', encoding='utf-8') as csv_file:
csv_reader = csv.DictReader(csv_file)
data = list(csv_reader)
with open(json_file_path, mode='w', encoding='utf-8') as json_file:
json.dump(data, json_file, indent=4, ensure_ascii=False)
print(f"Succès : Le fichier a été converti et enregistré sous {json_file_path}")
except FileNotFoundError:
print("Erreur : Le fichier CSV source est introuvable.")
except Exception as e:
print(f"Une erreur est survenue : {e}")Le plus gros modèle… mais le résultat le plus basique. Le code fonctionne, mais c'est le plus lent du benchmark (124.8 µs, presque 3× plus lent que Nemotron). Aucune flexibilité : pas de retour en mémoire, pas de paramètre d'encoding. La gestion d'erreur par print() avale les exceptions silencieusement.
Ironie : c'est le modèle le plus volumineux (31b) qui produit le code le moins intéressant. La taille du modèle n'est clairement pas corrélée à la qualité du code sur ce type de tâche.
Ce qu'on retient
La taille du modèle ne fait pas tout
Le classement final bouscule les attentes :
- Nemotron-cascade-2 — Le plus rapide, le plus flexible, le mieux typé
- ministral-3:14b — Un « petit » modèle qui a compris la subtilité du prompt
- devstral-small-2 — Minimaliste et efficace, zéro superflu
- qwen3.5:35b — Correct avec un bon détail technique (
newline='') - Gemma4:26b — Fonctionnel mais générique
- Gemma4:31b — Le plus lourd, le plus lent, le moins inspiré
Les patterns récurrents
Tous les modèles ont produit du code fonctionnel utilisant csv.DictReader + json.dump. Les différences se jouent sur :
- La gestion d'erreur : 4 modèles sur 6 utilisent
try/exceptavecprint(), un anti-pattern. Seuls Nemotron (qui lève uneFileNotFoundError) et devstral (qui ne gère pas les erreurs, ce qui est mieux que de les avaler) font un choix correct. - La flexibilité : seuls 2 modèles sur 6 (Nemotron et ministral) proposent un double mode fichier/mémoire. C'est pourtant une interprétation naturelle du prompt « transformer en JSON » qui ne précise pas la destination.
- Le style :
list(reader)vsfor row: append— les deux fonctionnent, maislist()est plus idiomatique et marginalement plus rapide.
Conseil pratique
Pour du code utilitaire simple, un modèle léger (14b) bien entraîné peut rivaliser avec des modèles 2× plus gros. Sur un serveur avec 2× Quadro P5000, les modèles jusqu'à ~35b tournent confortablement. Le meilleur rapport qualité/ressources ici : ministral-3:14b, qui donne un excellent résultat avec une empreinte mémoire GPU minimale.
Tests réalisés avec Python 3.13 sur un Intel Xeon W-2125 / 32 Go RAM / 2× Quadro P5000. Benchmark : 1 000 itérations par fonction, mesure mémoire via tracemalloc.